

Pythonにはデータ分析や機械学習のライブラリが豊富に存在します。scikit-learnもその1つで、オープンソースの機械学習ライブラリとして広く利用されています。
今回は、scikit-learnで何ができるのかということをまとめていきたいと思います。
特徴
scikit-learnの特徴は主に以下の通りです。
- データ分析による予測がシンプルかつ効果的に実装可能
- オープンソースで商用利用も可能
- NumpyやScipy、matplotlibと連携できるように設計されている
数値計算ライブラリのNumpyやグラフ描画ライブラリのmatplotlibとの連携が容易という点が特徴的です。これによって、データ分析の一連の流れをカバーできるので、データ分析におけるプログラミングのハードルを下げることができます。
scikit-learnでできること
ここからは、scikit-learnで何ができるのかをまとめていきます。
分類 – Classification
この手法では、データがどのカテゴリに属するかの分類を行います。

分類に用いるアルゴリズムとしては、SVM(サポートベクターマシン)、k近傍法、ランダムフォレストなどがあります。
分類は2次元だけでなく、多次元空間でも行うことができます。ナイーブベイズ等を用いると、多次元空間でも正確に分類することができたりします(今回は詳細は割愛します、)
回帰 – Regression
この手法では、結果となる数値(Y)と要因となる数値(X)の関係性を明らかにします。このときのYを目的変数(従属変数)、Xを説明変数(独立変数)と呼ぶ場合もあります。
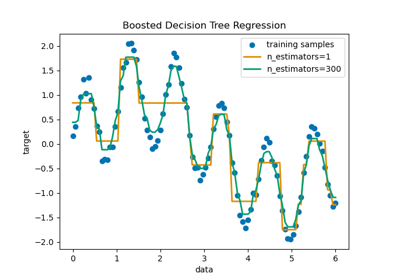
アルゴリズムとしては、SVR(サポートベクター回帰)、k近傍法、ランダムフォレストなどがあります。この他、線形回帰など基本的な回帰も実装されています。
ちなみに、説明変数(X)が1次元の場合は単回帰、2次元以上の場合は重回帰と言います。
クラスタリング – Clustering
クラスタリングは教師なしデータ分析の手法で、与えられたデータを外的基準なしに分類します。
アルゴリズムとしては、k-means法やward法、DBSCAN等があります。

次元削減 – Dimensionality reduction
次元削減とはデータの次元(特徴量)を減らすことです。多次元で構成されるデータを、その意味を保ちながら少ない次元のデータに変換します。
機械学習では使用するデータが膨大になりがちです。そのため、次元削減でデータ量を抑えることは、計算効率的にも非常に有効であるといえます。
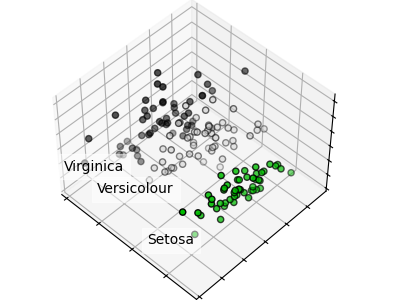
次元削減の最もメジャーな手法はPCA(主成分分析)です。PCAでは、元の情報を失わないように、主要な成分を抽出します。
scikit-learnを使えば、簡単にPCAも実装することができます。
検証モデル
機械学習では、予測や解析結果の妥当性を評価する必要があります。scikit-learnでは、それすら可能です。
検証手法に、交差検証というものがあります。この手法では、標本を分割し、一部を解析し、もう一方で解析のテストを行います。そして、各データが必ず一度はテストに割り当てられるまで検証を続けます。
こうして、データのサンプリングによる結果のばらつきを排除して精度の検証を行います。
データ前処理
scikit-learnではさらにデータの前処理も可能です。
例えば、データの正規化です。年齢と年収を想像してみてください。年齢は大体2桁の数値ですが、年収となると桁が大きく異なります(10000000とか、理想)。
これほど桁が異なるデータを扱うと、何かと不便もあります。そこで行う前処理が正規化です。これを行うと、データを指定した範囲内に圧縮することができます。例えば[-1, 1]を範囲に指定すると、この範囲内に収まるようにデータを圧縮してくれます。
こうすることで、桁が異なるデータを同等に扱うことができます。
機械学習におすすめ書籍
機械学習をこれから始めてみようという方には以下の書籍がオススメです。機械学習を実装するイメージを掴むことができます。
定番オライリーの「Pythonではじめる機械学習」では、解説も細かく、これ一冊でscikit-learnを用いた機械学習をほとんど網羅できてしまいます。
解説が細かい故に理解が難しいという方もいらっしゃるかもしれませんが、そんな方は他の書籍と併せて読むと理解が深まっていくかもしれません。
まとめ
Pythonライブラリのscikit-learnでできることについて紹介しました。numpyなどと相性がいいことから、機械学習をPythonでやるにあたって避けて通れないライブラリの1つだと思います。
今後は、具体的なscikit-learnの使い方も紹介していければと思います。
ではでは👋







