

グラフを描画する際には見せたい値を描画するだけでは不十分な場合があります。それは、標準偏差や標準誤差を一緒に示すのが好ましい場合です。
標準偏差や標準誤差を示すことで、そのデータがどれほどのばらついているのかということがわかります。学術誌などでは、これがないグラフは信ぴょう性が低い結果として扱われる場合もあります。
グラフにおける標準偏差や標準誤差はエラーバーなどと呼ばれます。今回は、Pythonライブラリのmatplotlibでエラーバー付きの棒グラフを描画する方法を紹介していきます。
用語確認
まずはじめに、標準偏差と標準誤差の意味についておさらいしておきます。
標準偏差
標準偏差の前に「分散」について押さえておく必要があります。分散はデータが平均周りでどれくらいばらついているかということを表す指標です。分散s2は以下の式で表されます。
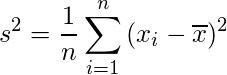
ここでnはデータの数、xiは各データの値、 はデータの平均値です。つまり、データの各値から平均を引いたものを二乗し、それを足し合わせた後データの数で割ったものが分散となるのです(式みりゃわかるって!?)。
はデータの平均値です。つまり、データの各値から平均を引いたものを二乗し、それを足し合わせた後データの数で割ったものが分散となるのです(式みりゃわかるって!?)。
ところが分散には1つ課題があります。それは、単位が元のデータと異なるという点です。例えば男性10人の体重を測定したとき、平均の単位は「kg」となります。しかし、分散の単位は「kg2」となってしまいます。これでは、平均と分散を比較したりすることができません。
そこで出てくるのが標準偏差です。標準偏差は分散の正の平方根のことを指し、σ(シグマ)で表されます。標準偏差も分散と同じく、標本(データ)がどの程度ばらついているかを示す指標とな
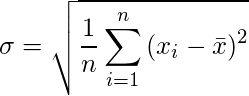
この値であれば、平均に足したり引いたりすることができる値となり、データのばらつきがより分かりやすくなります。
標準偏差は英語でstandard deviationといい、よくSDと略されます。
標準誤差
標準誤差は推定量の標準偏差のことで、母集団から抽出した標本から得られる推定量のばらつきを表します。標準誤差はstandard errorで、SEと略されます。
標準偏差は得られた標本(データ)のばらつきでしたが、標準誤差は母集団の予測値のばらつきです。予測値のような推定量を扱う場合は標本分散ではなく不偏分散を用います(説明はここでは割愛します)。なので、標準誤差は以下のように求まります。
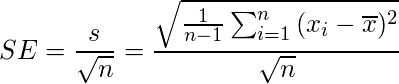
このときsは標準偏差ですが、母平均から抽出した標本をもとに推定される標準偏差です(nではなくn-1になっています)。
一般に、サンプルサイズが大きくなると標準誤差は小さくなります(分母にnがありますからね)。
また、標準偏差と比較しても小さい値となります(分母にnがありますからね)。
Pythonで描画
ここからはPythonを使ってグラフを描画してみます。
使用するデータ
今回はボストン住宅価格のデータセットを使用します。
import pandas as pd
from sklearn.datasets import load_boston
data = load_boston()
name = pd.DataFrame(data.target).rename(columns={0:"name"})
df = pd.DataFrame(data.data, columns=data.feature_names).merge(name, left_index=True, right_index=True)
df = pd.DataFrame(data.data, columns=data.feature_names)
“CHAS”列が2種類の値しか持っていないので、この列をベースに2つのデータに分割します。
#ユニークな値とカウント
df["CHAS"].value_counts()
>> 0.0 471
1.0 35
Name: CHAS, dtype: int64#"CHAS"の値でデータを分割
data_0 = df[df["CHAS"]==0]
data_1 = df[df["CHAS"]==1]グラフに使用する値
棒グラフには平均値を、エラーバーには標準偏差と標準誤差の2通りでプロットします。そのためのデータを用意します。
#平均
mean_0 = data_0["RM"].mean()
mean_1 = data_1["RM"].mean()
#標準偏差
std_0 = data_0["RM"].std()
std_1 = data_1["RM"].std()
#標準誤差
sem_0 = data_0["RM"].sem()
sem_1 = data_1["RM"].sem()グラフ描画
棒グラフはmatplotlibを使って描画します。まずはシンプルな平均のグラフを描画してみます(体裁は整えます)。
import matplotlib.pyplot as plt
x = [0,1]
y = [mean_0, mean_1]
plt.bar(x, y, width=0.6)
plt.xticks(x, fontsize=8)
plt.xlabel('RAD')
plt.ylabel('RM')![x = [0,1]y = [mean_0, mean_1] の棒グラフ](https://sp-ao.shortpixel.ai/client/to_webp,q_glossy,ret_img,w_376,h_261/https://www.learning-nao.com/wp-content/uploads/2022/02/image-1.png)
標準偏差を追加
棒グラフにエラーバーを追加するにはplt.bar()の引数にyerrを追加します。今回x軸の”RAD”は2つの値なので、要素数2の標準偏差の配列を作成し、yerrに渡します。
エラーバーの傘は引数capsizeで指定できます。
err = [sem_0, sem_1]err = [std_0, std_1]
plt.bar(x, y, width=0.6, yerr=err, capsize=10)
plt.xticks(x, fontsize=8)
plt.xlabel('RAD')
plt.ylabel('RM')
標準誤差を追加
今度は先ほどのグラフの標準偏差を標準誤差に置き換えてみます。
err = [sem_0, sem_1]
plt.bar(x, y, width=0.6, yerr=err, capsize=10)
plt.xticks(x, fontsize=8)
plt.xlabel('RAD')
plt.ylabel('RM')
Pythonでデータサイエンスするなら
Pythonでデータサイエンスをするなら、以下の書籍がおすすめです。Pandas、matplotlib、Numpy、scikit-learnといったデータサイエンスに必要なライブラリを、体系立てて一通り学ぶことができます。
ややお値段高めですが、これ1冊で十分という内容・ボリュームなので、損はしないと思います^^
まとめ
Pythonでエラーバー付きの棒グラフを描画する方法を紹介しました。
グラフとしてデータを見せる際は、そのデータがどれほどバラついているのかというのは非常に重要な情報です。標準偏差や標準誤差の意味合いを把握したうえで、データを図示するようにしてください^^
ではでは👋







