

統計の勉強をしていると、t分布というワードに出くわします。母平均の区間推定をする際などに出てきますが、t分布とか難しそうなので後回しに、、というケースもあるあるだと思います(?)。
そこで今回は、t分布とはいったい何者なのかということを探っていこうと思います。実際にPythonでコードを書きながら、実践検証もしていこうと思います。読み終わったころには、t分布について少し理解が深まっていればうれしいです^^
t分布の定義
正規分布に似た分布ですが、t分布は不偏推定量を用います(正規分布は母数を用いる)。
母平均の区間推定をする場面を考えてみます。母分散σ2がわかっている場合、母平均の95%信頼区間を求める式は以下のようになります。
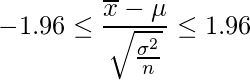
中央の式は標本平均を標準化する式です。このときμは母平均、 は標本平均です。μについて式変形をすると以下の式になります。
は標本平均です。μについて式変形をすると以下の式になります。
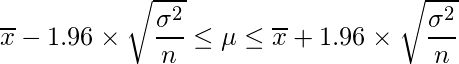
の分布は、nが大きくなるにつれて平均μ、分散σ2/nの正規分布に近づきます(中心極限定理)。上式で標本平均を標準化しているのは、標準正規分布を利用しているためです。
しかしながら、母平均がわかっていないのに母分散がわかっているケースなどこの世ではほとんどありません。なので多くの場合、上記の式を母平均の区間推定に用いることはできません。
母分散がわからないときに何を使えばよいかと言えば、「不偏分散」です。不偏分散s2を用いて区間推定をする場合標準正規分布ではなく「t分布」を用います。t分布は以下の式が従う確率分布です。
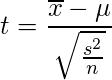
標準正規分布の場合のσ2がs2に置き換わったものがt分布です。
t分布の形
それではt分布とは一体どんな形をしているのでしょうか。t分布は標準正規分布とよく似た形の分布をしています(違いがσ2かs2ですからね)。t分布は自由度によってその分布の形が変わってきます。
実際にPythonでt分布を描いてみます。自由度(degree of freedom:df)が大きくなるほど、標準正規分布に近づいていきます。今回は自由度が1から4までのt分布と標準正規分布をプロットします。
t分布の作成にはscipyのstats.tを用います。pdf()は確率密度関数を返します。
同様に、正規分布の作成にはstats.normを用います。
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
#-3から3の範囲で100等分
x = np.linspace(-3, 3, 100)
for df in range(1, 5):
#t分布作成
t = stats.t.pdf(x, df)
plt.plot(x, t, label=f"df={df}")
#標準正規分布作成
norm = stats.norm.pdf(x, loc=0, scale=1)
plt.plot(x, norm, label="norm")
plt.legend()
確かに、自由度1のt分布よりも自由度4のt分布のほうが標準正規分布に近い形をしています。これはつまり、自由度が大きい(標本が大きい)場合は、t分布じゃなくて標準正規分布として考えてもいいということです。
また、自由度が小さい分布ほど山の裾が長くなっています。これは、95%信頼区間が広くなっているということを意味します。自由度が上がるにつれ裾は短くなり、95%信頼区間は短くなっていきます。そして標準正規分布の山の裾が短く、95%信頼区間も短いです。
つまり、母平均を求めるにあたって母分散σ2を用いる場合(標準正規分布)よりも、不偏分散s2を用いる場合(t分布)の方が、推定区間を広くとる必要があるということです。
推定値を使って推定するほうが予想の範囲が広くなるということは直感的にも理解できると思います。
t分布を使った母平均の区間推定
ここまでの内容を踏まえ、実際にt分布を用いて母平均の区間推定をやってみます。オーストラリアの天気データを使ってみます。
まずはデータを読み込みます。
import pandas as pd
df = pd.read_csv("weatherAUS.csv").dropna(subset = ['MaxTemp'])
“MaxTemp”列の母平均を推定したいので、当該列の欠損行は削除しています。まず答えとなる母平均を求めてみます。
df["MaxTemp"].mean()
>> 23.221348275647003ということで、このdfから標本を無作為に抽出し、抽出したデータから母平均を推定してみます。
まずは14万件あるdfから2000行をランダムにサンプリングします。そして、その2000行分のデータの平均値を算出します。df(データフレーム)からサンプルを取得するにはsample()を用います。引数nにはサンプリングする標本数を指定します。
n=2000
df_sample = df.sample(n=n)
df_sample["MaxTemp"].mean()
>> 23.184600000000028母平均とは異なる値になりました。これが標本平均です。では、t分布から母平均の95%信頼区間を求めてみます。
t分布で信頼区間を求めるにはscipyのstats.t.interval()を用います。
scipy.stats.t.interval(alpha, loc, scale, df)
alphaは信頼区間、locは標本平均、scaleは標本の標準偏差, dfには自由度を指定します。
t分布を用いた区間推定では自由度はn-1となることに注意してください。
from scipy import stats
sample_mean = df_sample["MaxTemp"].mean()
sample_std = df_sample["MaxTemp"].std(ddof=1)
#区間推定
stats.t.interval(alpha=0.95, loc=sample_mean, scale=sample_std/np.sqrt(n), df=n-1)
>> (22.871348352496238, 23.49785164750382)結果、22.87~23.49の間に母平均が存在するということがわかりました。実際、母平均は23.22だったので、推定の結果は正しいということがわかります。
Pythonでデータサイエンスするなら
Pythonでデータサイエンスをするなら、以下の書籍がおすすめです。Pandas、matplotlib、Numpy、scikit-learnといったデータサイエンスに必要なライブラリを、体系立てて一通り学ぶことができます。
ややお値段高めですが、これ1冊で十分という内容・ボリュームなので、損はしないと思います^^
まとめ
t分布について、Pythonを使いながら探っていきました。特に、t分布と標準正規分布はよく似ていることが見て取れました。
t分布は統計学でよく出てくるトピックです。数式だけ見て苦手意識を持ってしまわないよう、内容を細かく分けてみたり、図を通してみたりしながら少しずつ理解を深めていきたいですね^^
ではでは👋







