

Pythonでは、数値計算ライブラリであるNumpyを用いることで、正規分布に従うデータを作成することができます。
本記事では、正規分布とは?というところから、Numpyで任意の正規分布データを作成する方法を紹介します。
正規分布とは
正規分布とは統計学でよく用いられる連続型確率分布で、ガウス分布とも呼ばれます。正規分布は以下の図のような左右対称の形をしています。

このとき横軸は確率変数、縦軸は確率密度を表します。正規分布では、平均値と中央値が等しくなり、それらは最頻値とも等しくなります。つまり、上図の頂点となるところが平均値であり、中央値となります。
確率変数Xが平均μ、分散σ2の正規分布に従うとき、確率密度関数f(x)は以下のように表されます。
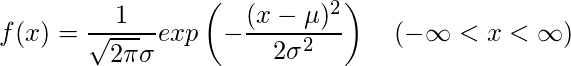
正規分布に従う確率変数Xの期待値(E(X))および分散(V(X))は以下のようになります。
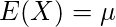
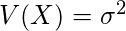
また、平均0、分散1の正規分布は特に標準正規分布と呼ばれます。分散が1なので、標準正規分布に従う確率変数Xの確率密度関数f(x)は以下のように表せます。
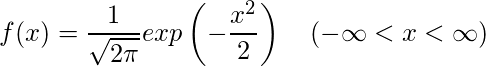
Pythonで正規分布データを作る
Numpyで作る
自力で計算
まずは上記の式に従って自力で計算し、データを作成してみます。
import numpy as np
x = np.linspace(-10, 10, 101) # 区間[-10,10]を100等分する101点
print(x)
y = np.exp(-x**2 / 2) / np.sqrt(2 * np.pi)
print(y)
##array([-10. , -9.8, -9.6, -9.4, -9.2, -9. , -8.8, -8.6, -8.4,
-8.2, -8. , -7.8, -7.6, -7.4, -7.2, -7. , -6.8, -6.6,
-6.4, -6.2, -6. , -5.8, -5.6, -5.4, -5.2, -5. , -4.8,
-4.6, -4.4, -4.2, -4. , -3.8, -3.6, -3.4, -3.2, -3. ,
-2.8, -2.6, -2.4, -2.2, -2. , -1.8, -1.6, -1.4, -1.2,
-1. , -0.8, -0.6, -0.4, -0.2, 0. , 0.2, 0.4, 0.6,
0.8, 1. , 1.2, 1.4, 1.6, 1.8, 2. , 2.2, 2.4,
2.6, 2.8, 3. , 3.2, 3.4, 3.6, 3.8, 4. , 4.2,
4.4, 4.6, 4.8, 5. , 5.2, 5.4, 5.6, 5.8, 6. ,
6.2, 6.4, 6.6, 6.8, 7. , 7.2, 7.4, 7.6, 7.8,
8. , 8.2, 8.4, 8.6, 8.8, 9. , 9.2, 9.4, 9.6,
9.8, 10. ])
##array([7.69459863e-23, 5.57300002e-22, 3.87811193e-21, 2.59286470e-20,
1.66558803e-19, 1.02797736e-18, 6.09575813e-18, 3.47296275e-17,
1.90108154e-16, 9.99837875e-16, 5.05227108e-15, 2.45285529e-14,
1.14415649e-13, 5.12775364e-13, 2.20798996e-12, 9.13472041e-12,
3.63096150e-11, 1.38667999e-10, 5.08814028e-10, 1.79378391e-09,
6.07588285e-09, 1.97731964e-08, 6.18262050e-08, 1.85736184e-07,
5.36103534e-07, 1.48671951e-06, 3.96129909e-06, 1.01408521e-05,
2.49424713e-05, 5.89430678e-05, 1.33830226e-04, 2.91946926e-04,
6.11901930e-04, 1.23221917e-03, 2.38408820e-03, 4.43184841e-03,
7.91545158e-03, 1.35829692e-02, 2.23945303e-02, 3.54745928e-02,
5.39909665e-02, 7.89501583e-02, 1.10920835e-01, 1.49727466e-01,
1.94186055e-01, 2.41970725e-01, 2.89691553e-01, 3.33224603e-01,
3.68270140e-01, 3.91042694e-01, 3.98942280e-01, 3.91042694e-01,
3.68270140e-01, 3.33224603e-01, 2.89691553e-01, 2.41970725e-01,
1.94186055e-01, 1.49727466e-01, 1.10920835e-01, 7.89501583e-02,
5.39909665e-02, 3.54745928e-02, 2.23945303e-02, 1.35829692e-02,
7.91545158e-03, 4.43184841e-03, 2.38408820e-03, 1.23221917e-03,
6.11901930e-04, 2.91946926e-04, 1.33830226e-04, 5.89430678e-05,
2.49424713e-05, 1.01408521e-05, 3.96129909e-06, 1.48671951e-06,
5.36103534e-07, 1.85736184e-07, 6.18262050e-08, 1.97731964e-08,
6.07588285e-09, 1.79378391e-09, 5.08814028e-10, 1.38667999e-10,
3.63096150e-11, 9.13472041e-12, 2.20798996e-12, 5.12775364e-13,
1.14415649e-13, 2.45285529e-14, 5.05227108e-15, 9.99837875e-16,
1.90108154e-16, 3.47296275e-17, 6.09575813e-18, 1.02797736e-18,
1.66558803e-19, 2.59286470e-20, 3.87811193e-21, 5.57300002e-22,
7.69459863e-23])np.linspace()は始点、終点、区間を指定することで、均等な間隔の配列を作成できます。上の例では、-10から10までの間を100等分した101点が得られます。
yは確率密度関数f(x)の計算式そのものです。
作ったデータをプロットしてみます。
import matplotlib.pyplot as plt
plt.plot(x, y)
きれいな正規分布になっていることがわかります。
正規分布に従う乱数
Numpyでは、正規分布に従う乱数を生成することもできます。np.random.normal()を用います。
np.random.normal(loc, scale, size)
locは平均、scaleは標準偏差を指定します。sizeは配列の要素数を指定します。一次元の場合は整数、二次元の場合はタプルで指定します。
平均5、標準偏差6、サイズ1000の乱数を生成する場合は以下のように記述します。
rnd = np.random.normal(loc=5.0, scale=6.0, size=1000)正規分布に従っているか確かめるためにヒストグラムを描いてみます。

正規分布っぽい感じになっています。サンプルサイズが大きければ大きいほど、きれいな正規分布になります。
標準正規分布の乱数
np.random.randn()を用いれば、標準正規分布(平均0、標準偏差1)に従う乱数を生成することができます。
np.random.randn(size)
平均、標準偏差は固定なので、サイズを指定するだけです。
#サンプルサイズ1000
arr = np.random.randn(1000)
【おまけ】Scipyで作る
ScipyならNumpyの時のように計算式を書かずとも関数が用意されています。scipy.stats.norm.pdf()を用います。pdfとは、確率密度関数(probability density function)の頭文字です。
from scipy.stats import norm
x = np.linspace(-10, 10, 101) # 区間[-10,10]を100等分する101点
y = norm.pdf(x)
plt.plot(x, y)
複雑な計算式は書きたくないという方はこのやり方がおすすめです(コードを見ても直感的にわかりやすいですしね)。
Pythonでデータサイエンスするなら
Pythonでデータサイエンスをするなら、以下の書籍がおすすめです。Pandas、matplotlib、Numpy、scikit-learnといったデータサイエンスに必要なライブラリを、体系立てて一通り学ぶことができます。
ややお値段高めですが、これ1冊で十分という内容・ボリュームなので、損はしないと思います^^
まとめ
PythonのNumpyで正規分布に従うデータを生成する方法を紹介しました。
正規分布は統計学をはじめデータ分析の分野で非常によく使われます。どういった特徴かを理解して使っていきましょう^^
ではでは👋







