

多くの場合、ある集団の真の平均(母平均)は闇に包まれています。
たとえば、世界中の全ての男性の平均身長を正確に割り出すには、全ての男性の身長を測定しなければなりません。そんなん無理です。
こういった場合には、一部のサンプルからだいたいこれくらいの範囲に平均が収まるであろうという推測をします。それが母平均の区間推定です。
Pythonを使えば、データさえあれば簡単に母平均の区間推定ができます。今回はt分布を使った母平均の区間推定を紹介していきます。
使用するデータ
今回はボストン住宅価格のデータセットを使っていこうと思います。
import pandas as pd
from sklearn.datasets import load_boston
from datetime import datetime, timedelta
data = load_boston()
name = pd.DataFrame(data.target).rename(columns={0:"name"})
df = pd.DataFrame(data.data, columns=data.feature_names).merge(name, left_index=True, right_index=True)
区間推定
“RM”列の母平均を区間推定してみます。前提として、”RM”は正規分布に従っているという仮定します。一応、”RM”の分布を確認しておきます。
import matplotlib.pyplot as plt
data = df["RM"]
plt.hist(data)
正規分布、、って感じですが、一応サンプルなので今回は目をつむることにします。
区間推定で求める範囲は、〇〇%の確率で母平均がその範囲に入っているという範囲です。例えば95%の確率で母平均が収まる範囲のことを「95%信頼区間」と呼びます。
このとき95%信頼区間とは、「母集団から取り出した標本の平均から95%信頼区間を求めたときに、95%の確率で母平均が含まれている」ということではないので注意してください。
95%信頼区間は確率ではなく割合を表します。つまり正確には、「母集団から取り出した標本の平均から95%信頼区間を求めるということを100回繰り返したときに、95回はその区間に母平均が含まれる」ということを意味します。
奇跡的に母分散がわかっている場合
母平均がわかってないのに母分散だけわかっているなんて摩訶不思議な場面は数学の教科書以外ではほとんどありません。
なので割愛します。
母分散がわからない場合
数学的背景
統計量tがt分布の〇〇%の面積の範囲内に収まることを考えます。95%信頼区間を求める場合は統計量tがt分布の95%の面積の範囲内に収まることを考えます。
母平均をμ、不偏分散をs2としたとき、統計量tは以下の式で求められます。
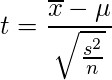
このとき、統計量は自由度n-1のt分布に従います。これを利用すると、母平均μの(100(1-α))%信頼区間は以下の式で求めることができます。
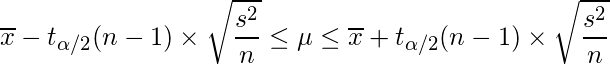
pythonで求める
Pythonを使えば上記のややこしい式は意識せず、パラメータとなる数値さえわかっていれば信頼区間を求めることができます。
まずはパラメータを求めます。
import math
from scipy.stats import norm
#不偏分散
var = df["RM"].var()
#平均
mean = df["RM"].mean()
#自由度
deg_of_freedom = len(df["RM"]) - 1
#標準偏差(統計量tの分母)
scale = math.sqrt(var/len(df["RM"]))Pythonでt分布を用いた区間推定をするには、scipy.statsのtを用います。interval()を使えば、戻り値で区間の最小、最大値を取得できます。
scipy.stats.t.interval(alpha, df, loc, scale)
alphaは信頼区間の%、dfは自由度、locは標本平均、scaleは標本の標準偏差です。実際にPythonで書いたスクリプトは以下の通りです。
from scipy.stats import t
bottom, up = t.interval(0.95, deg_of_freedom, loc=mean, scale=scale)
print(bottom)
print(up)
>>6.223267558636063
6.346001216067511“RM”の95%信頼区間が得られました。
まとめ
Pythonでt分布を用いた母平均の区間推定をやってみました。
Pythonだと原理をわかってなくても統計の計算が簡単にできてしまうので、便利ですが用法を間違わないようにしたいですね(主に自戒)。
ではでは👋







